Store and access your data #
Kuzzle uses Elasticsearch as a document-oriented storage.
All documents, whether internal documents such as User, Profile or Role or user documents, are stored in Elasticsearch indexes.
Kuzzle's storage capacities are therefore directly linked to Elasticsearch's capacities and limits.
Data storage organization #
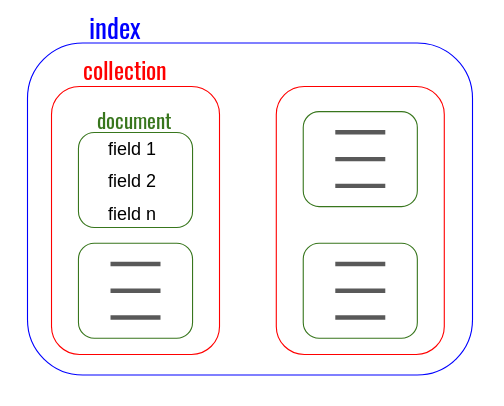
There are 4 hierarchical levels in data storage:
- indexes
- collections
- documents
- fields
An index brings together several collections, which in turn contains several documents, each of which is composed of several fields.
Comparison with a relational database #
Even if Elasticsearch is not, strictly speaking, a database, the way it stores data is very similar to that of document-oriented databases.
If you're more familiar with the way relational databases store data, here is how it compares:
| Document-oriented storage | Relational databases storage |
|---|---|
| index | database |
| collection | table |
| document | line |
| field | column |
Comparing document-oriented storages with relational databases would require a more thorough analysis, but for the purposes of this guide, we shall reduce the list of differences to the following 3 items:
- Documents are identified with a unique identifier, which is stored separately from the content of documents (compared to primary/foreign keys, stored alongside the data they identify),
- no advanced join system,
- a typed mapping system to define how Elasticsearch should index the fields.
All these differences should be taken into account when modeling your data model and your application.
Creating indexes and collections #
The creation of indexes and collections is done through the API via the methods index:create and collection:create.
For example, to create a nyc-open-data index:
curl -X POST localhost:7512/nyc-open-data/_create?pretty
Click to see Kuzzle API answer
{
"requestId": "e9ab8d1a-ea1a-4fdd-ad50-07c82245d88c",
"status": 200,
"error": null,
"controller": "index",
"action": "create",
"collection": null,
"index": "nyc-open-data",
"volatile": null,
"result": {
"acknowledged": true,
"shards_acknowledged": true,
"index": "nyc-open-data"
}
}
Then a yellow-taxi collection in this index:
It is recommended to specify a data mapping when creating a collection so that its content can correctly be indexed by Elasticsearch.
curl -X PUT localhost:7512/nyc-open-data/yellow-taxi?pretty
Click to see Kuzzle API answer
{
"requestId": "1d5b7afe-9d81-4c0e-92bc-aa57b24c35eb",
"status": 200,
"error": null,
"controller": "collection",
"action": "create",
"collection": "yellow-taxi",
"index": "nyc-open-data",
"volatile": null,
"result": {
"acknowledged": true
}
}
It is also possible to define in advance a set of indexes and collections, then load them at the start of Kuzzle (option --mappings, via the CLI or with the API method admin:loadMappings
Writing documents #
The Kuzzle API offers several methods to create, modify or delete documents in its storage space.
Each of these methods has its own specificities, we can distinguish two main families of methods: those acting on a document and those acting on multiple documents.
Methods acting on a single document:
- document:create: creates a new document
- document:createOrReplace: creates a new document or replaces an existing one
- document:delete: deletes a document
- document:replace: replaces an existing document
- document:update: updates fields in an existing document
Methods acting on multiple documents
- document:deleteByQuery: deletes documents matching an Elasticsearch query
- document:mCreate: creates multiple documents
- document:mCreateOrReplace: creates or replaces multiple documents
- document:mDelete: deletes multiple documents
- document:mReplace: replaces multiple documents
- document:mUpdate: updates fields of multiple documents
The bulk controller features low-level methods for injecting documents in collections.
For example, to create a new document in our index:
curl -X POST -H "Content-Type: application/json" -d '{ "driver": "liia", "arriveAt": "2019-07-26" }' http://localhost:7512/nyc-open-data/yellow-taxi/document-uniq-id/_create?pretty
Click to see Kuzzle's answer
{
"requestId": "e146e2a5-ff5b-4b6f-a603-8cde43f353fe",
"status": 200,
"error": null,
"controller": "document",
"action": "create",
"collection": "yellow-taxi",
"index": "nyc-open-data",
"volatile": null,
"result": {
"_index": "nyc-open-data",
"_type": "yellow-taxi",
"_id": "document-uniq-id", // Document ID
"_version": 1,
"result": "created",
"created": true,
"_source": { // Document body
"driver": "liia",
"arriveAt": "2019-07-26",
"_kuzzle_info": { // Kuzzle metadata
"author": "-1",
"createdAt": 1561443009768,
"updatedAt": null,
"updater": null,
"active": true,
"deletedAt": null
}
}
}
}
Using the document:update method allows us to add a new field while keeping the old ones:
curl -X PUT -H "Content-Type: application/json" -d '{ "car": "rickshaw" }' http://localhost:7512/nyc-open-data/yellow-taxi/document-uniq-id/_update?pretty
Click to see Kuzzle's answer
{
"requestId": "1be6c9e6-2626-4f85-ad64-d1cc248c7bee",
"status": 200,
"error": null,
"controller": "document",
"action": "update",
"collection": "yellow-taxi",
"index": "nyc-open-data",
"volatile": null,
"result": {
"_index": "nyc-open-data",
"_type": "yellow-taxi",
"_id": "document-uniq-id",
"_version": 2,
"result": "updated"
}
}
Reading documents #
There are two ways to retrieve documents:
- using the document unique identifiers,
- by performing a search with an Elasticsearch query.
Getting documents #
To retrieve a document when you know its unique identifier, you have to use the document:get or the document:mGet method.
For example, to retrieve the documents we created in the previous examples:
curl http://localhost:7512/nyc-open-data/yellow-taxi/document-uniq-id?pretty
Click to see Kuzzle's answer
{
"requestId": "62af64c8-5dc6-48c1-942b-2604bf97686e",
"status": 200,
"error": null,
"controller": "document",
"action": "get",
"collection": "yellow-taxi",
"index": "nyc-open-data",
"volatile": null,
"result": {
"_index": "nyc-open-data",
"_type": "yellow-taxi",
"_id": "document-uniq-id",
"_version": 2,
"found": true,
"_source": {
"driver": "liia",
"arriveAt": "2019-07-26",
"_kuzzle_info": {
"author": "-1",
"createdAt": 1561443222474,
"updatedAt": 1561443279526,
"updater": "-1",
"active": true,
"deletedAt": null
},
"car": "rickshaw"
}
}
}
Searching documents #
Searching documents is performed using the Elasticsearch Query DSL.
As Elasticsearch is an indexing engine designed for document search, it offers a wide range of advanced search options like geo queries, full text queries, aggregations, and more.
Requests must be made through Kuzzle using the document:search method.
When a document is created or modified, its latest version is not immediately available in the results of a search.
First, you have to wait until Elasticsearch has finished updating its index.
It is possible to makes Elasticsearch wait for the indexation before sending the answer by setting refresh=wait_for. It's also possible to wait indexation after every requests before sending the answer with index:setAutoRefresh.
For example, to retrieve documents between the ages of 25 and 28:
# First create some documents
for i in {18..42}; do; curl -X POST -H "Content-Type: application/json" -d "{ \"driver\": \"driver-$i\", \"age\": $i }" http://localhost:7512/nyc-open-data/yellow-taxi/_create &; sleep 0.05; done
# Search for drivers between 25 and 28 years
curl -X POST -H "Content-Type: application/json" -d '{
"query": {
"range": {
"age": { "gte": 25, "lte": 28 }
}
}
}
' http://localhost:7512/nyc-open-data/yellow-taxi/_search?pretty
Click to see Kuzzle's answer
{
"requestId": "836768a4-0b46-447a-b4c5-8932101f24de",
"status": 200,
"error": null,
"controller": "document",
"action": "search",
"collection": "yellow-taxi",
"index": "nyc-open-data",
"volatile": null,
"result": {
"took": 12,
"timed_out": false,
"hits": [
{
"_index": "nyc-open-data",
"_type": "yellow-taxi",
"_id": "AWuNXWff6MDMyQmSeEuT",
"_score": 1,
"_source": {
"driver": "driver-27",
"age": 27,
"_kuzzle_info": {
"author": "-1",
"createdAt": 1561444837342,
"updatedAt": null,
"updater": null,
"active": true,
"deletedAt": null
}
}
},
{
"_index": "nyc-open-data",
"_type": "yellow-taxi",
"_id": "AWuNXWd46MDMyQmSeEuR",
"_score": 1,
"_source": {
"driver": "driver-25",
"age": 25,
"_kuzzle_info": {
"author": "-1",
"createdAt": 1561444837239,
"updatedAt": null,
"updater": null,
"active": true,
"deletedAt": null
}
}
},
{
"_index": "nyc-open-data",
"_type": "yellow-taxi",
"_id": "AWuNXWgQ6MDMyQmSeEuU",
"_score": 1,
"_source": {
"driver": "driver-28",
"age": 28,
"_kuzzle_info": {
"author": "-1",
"createdAt": 1561444837391,
"updatedAt": null,
"updater": null,
"active": true,
"deletedAt": null
}
}
},
{
"_index": "nyc-open-data",
"_type": "yellow-taxi",
"_id": "AWuNXWer6MDMyQmSeEuS",
"_score": 1,
"_source": {
"driver": "driver-26",
"age": 26,
"_kuzzle_info": {
"author": "-1",
"createdAt": 1561444837290,
"updatedAt": null,
"updater": null,
"active": true,
"deletedAt": null
}
}
}
],
"total": 4,
"max_score": 1
}
}
What Now? #
- Exploit the full capabilites of Elasticsearch with Data Mappings
- Read our Elasticsearch Cookbook to learn more about how querying works in Kuzzle
- Use document metadata to find or recover documents
- Keep track of data changes using Real-time Notifications